SE0-Como salva o Tráfego que Ainda não Perdemos
Read Time:9 Minute, 16 Second
Você já tentou levar sua roupa limpa para cima com as mãos e coisas continuaram caindo da massa gigante de roupa que você carrega? Isso é muito parecido com tentar aumentar o tráfego orgânico do site.
Seu calendário de conteúdo é carregado com novas ideias, mas com cada página da web publicada, uma página mais antiga cai no ranking do mecanismo de pesquisa.
Obter tráfego de SEO é difícil, mas manter o tráfego de SEO é outro jogo de bola. O conteúdo tende a “decair” com o tempo devido a novos conteúdos criados por concorrentes, algoritmos de mecanismo de pesquisa em constante mudança ou uma miríade de outros motivos.
Você está lutando para fazer todo o site avançar, mas as coisas continuam vazando tráfego onde você não está prestando atenção.
O problema com o crescimento do tráfego
No HubSpot, aumentamos nosso tráfego orgânico fazendo duas viagens saindo da lavanderia em vez de uma.
A primeira viagem é com novo conteúdo, visando novas palavras-chave que ainda não classificamos.
A segunda viagem é com conteúdo atualizado, dedicando uma parte do nosso calendário editorial para descobrir qual conteúdo está perdendo mais tráfego – e leads – e reforçando-o com novos conteúdos e manobras de SEO que atendam melhor a determinadas palavras-chave. É um conceito que nós (e muitos profissionais de marketing) chamamos de ” otimização histórica “.
Mas, há um problema com essa estratégia de crescimento.
À medida que o tráfego do nosso site aumenta, rastrear cada página pode ser um processo indisciplinado. Selecionar as páginas certas para atualizar é ainda mais difícil.
No ano passado, nos perguntamos se havia uma maneira de encontrar postagens de blog cujo tráfego orgânico está meramente “em risco” de diminuir, para diversificar nossas opções de atualização e talvez tornar o tráfego mais estável conforme nosso blog fica maior.
Restaurando o Tráfego vs. Protegendo o Tráfego
Antes de falarmos sobre o absurdo de tentar restaurar o tráfego que ainda não perdemos, vejamos os benefícios.
Ao visualizar o desempenho de uma página, o declínio do tráfego é fácil de detectar. Para a maioria dos profissionais de marketing voltados para o crescimento, a linha de tendência de tráfego que aponta para baixo é difícil de ignorar, e não há nada tão satisfatório quanto ver essa tendência se recuperar.
Mas toda recuperação de tráfego tem um custo: porque você não pode saber onde está perdendo tráfego até que o tenha perdido, o tempo entre o declínio do tráfego e sua recuperação é um sacrifício de leads, demonstrações, usuários gratuitos, assinantes, ou alguma métrica semelhante de crescimento proveniente de seus visitantes mais interessados.
Você pode ver isso visualizado no gráfico de tendência orgânica abaixo, para uma postagem individual do blog. Mesmo com a economia de tráfego, você perdeu oportunidades de apoiar seus esforços de vendas subsequentes.
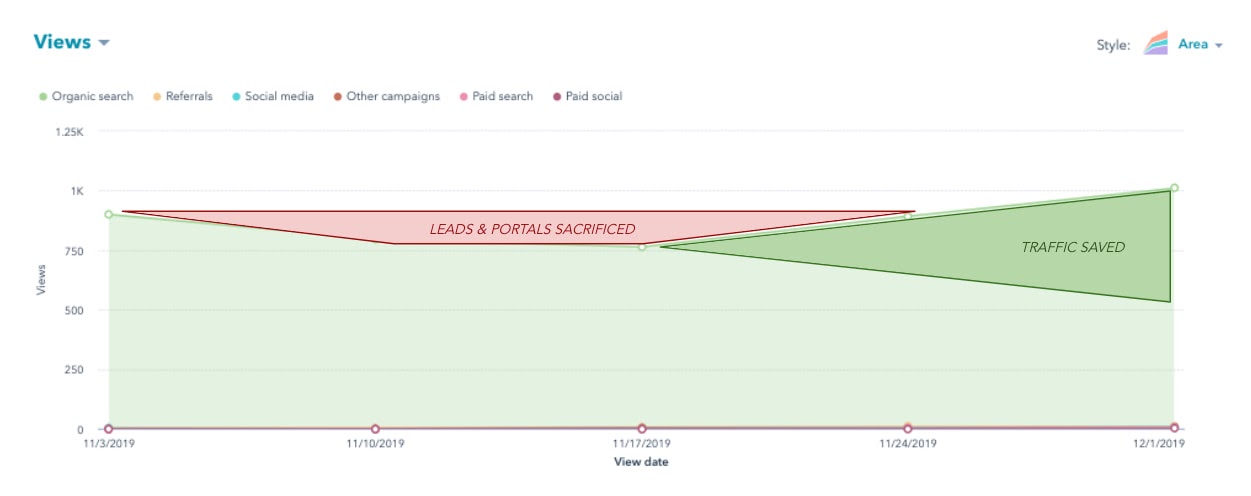
Se você tivesse uma maneira de encontrar e proteger (ou até mesmo aumentar) o tráfego da página antes que ela precise ser restaurada, você não teria que fazer o sacrifício mostrado na imagem acima. A questão é: como fazemos isso?
Como prever a queda do tráfego
Para nossa alegria, não precisávamos de uma bola de cristal para prever o atrito do tráfego. O que precisávamos, no entanto, eram dados de SEO que sugerissem que poderíamos ver o tráfego ir embora para postagens de blog específicas se algo continuasse. (Também precisávamos escrever um script que pudesse extrair esses dados para todo o site – mais sobre isso em um minuto.)
A alta classificação de palavras-chave é o que gera tráfego orgânico para um site. Não apenas isso, mas a maior parte do tráfego vai para sites que têm a sorte de ser classificados na primeira página. Essa recompensa pelo tráfego é ainda maior para palavras-chave que recebem um número particularmente alto de pesquisas por mês.
Se um post de blog escorregasse da primeira página do Google, para aquela palavra-chave de alto volume, é brinde.
Tendo em mente a relação entre palavras-chave, volume de pesquisa de palavras-chave, posição de classificação e tráfego orgânico, sabíamos que veríamos o prelúdio de uma perda de tráfego.
E, felizmente, as ferramentas de SEO à nossa disposição podem nos mostrar essa derrapagem na classificação ao longo do tempo:
A imagem acima mostra uma tabela de palavras-chave para as quais uma única postagem do blog é classificada.
Para uma dessas palavras-chave, esta postagem do blog está na posição 14 (a página 1 do Google consiste nas posições de 1 a 10). As caixas vermelhas mostram essa posição no ranking, bem como o grande volume de 40.000 pesquisas mensais dessa palavra-chave.
Ainda mais triste do que a 14ª posição deste artigo é como isso aconteceu.
Como você pode ver na linha de tendência azul-petróleo acima, esta postagem do blog já foi um resultado de alto nível, mas caiu consistentemente nas semanas seguintes. O tráfego da postagem corroborou o que vimos – uma queda perceptível nas visualizações orgânicas da página logo após a postagem sair da página 1 para esta palavra-chave.
Você pode ver onde isso está indo … queríamos detectar essas quedas na classificação quando elas estavam prestes a sair da página 1 e, ao fazer isso, restaurar o tráfego que estávamos “em risco” de perder. E queríamos fazer isso automaticamente, para dezenas de postagens de blog por vez.

A ferramenta de tráfego “em risco”
A forma como a ferramenta At Risk funciona é, na verdade, um tanto simples. Nós pensamos nisso em três partes:
- Onde obtemos nossos dados de entrada?
- Como o limpamos?
- Quais são os resultados desses dados que nos permitem tomar melhores decisões ao otimizar o conteúdo?
Primeiro, onde obtemos os dados?
1. Dados de palavras-chave de SEMRush
O que queríamos eram dados de pesquisa de palavras-chave em nível de propriedade. Portanto, queremos ver todas as palavras-chave classificadas como hubspot.com, especialmente blog.hubspot.com, e todos os dados associados que correspondem a essas palavras-chave.
Alguns campos que são valiosos para nós são nossa classificação atual do mecanismo de pesquisa, nossa classificação anterior do mecanismo de pesquisa, o volume de pesquisa mensal dessa palavra-chave e, potencialmente, o valor (estimado com dificuldade de palavra-chave ou CPC) dessa palavra-chave.
Para obter esses dados, usamos a API SEMrush (especificamente, usamos o relatório “Palavras-chave de pesquisa orgânica do domínio”):
Usando R , uma linguagem de programação popular para estatísticos e analíticos , bem como para profissionais de marketing (especificamente, usamos a biblioteca ‘httr’ para trabalhar com APIs), extraímos as 10.000 palavras-chave principais que direcionam o tráfego para blog.hubspot.com (também como nossas propriedades em espanhol, alemão, francês e português). Atualmente fazemos isso uma vez por trimestre.
São muitos dados brutos, que por si só são inúteis. Portanto, temos que limpar os dados e transformá-los em um formato que seja útil para nós.
Em seguida, como realmente limpamos os dados e criamos fórmulas para nos dar algumas respostas sobre qual conteúdo atualizar?
2. Limpando os dados e construindo as fórmulas
Fazemos a maior parte da limpeza de dados em nosso script R também. Portanto, antes que nossos dados cheguem a outra fonte de armazenamento de dados (seja planilhas ou uma tabela de dados de banco de dados), nossos dados são, em sua maior parte, limpos e formatados como queremos.
Fazemos isso com algumas linhas curtas de código:
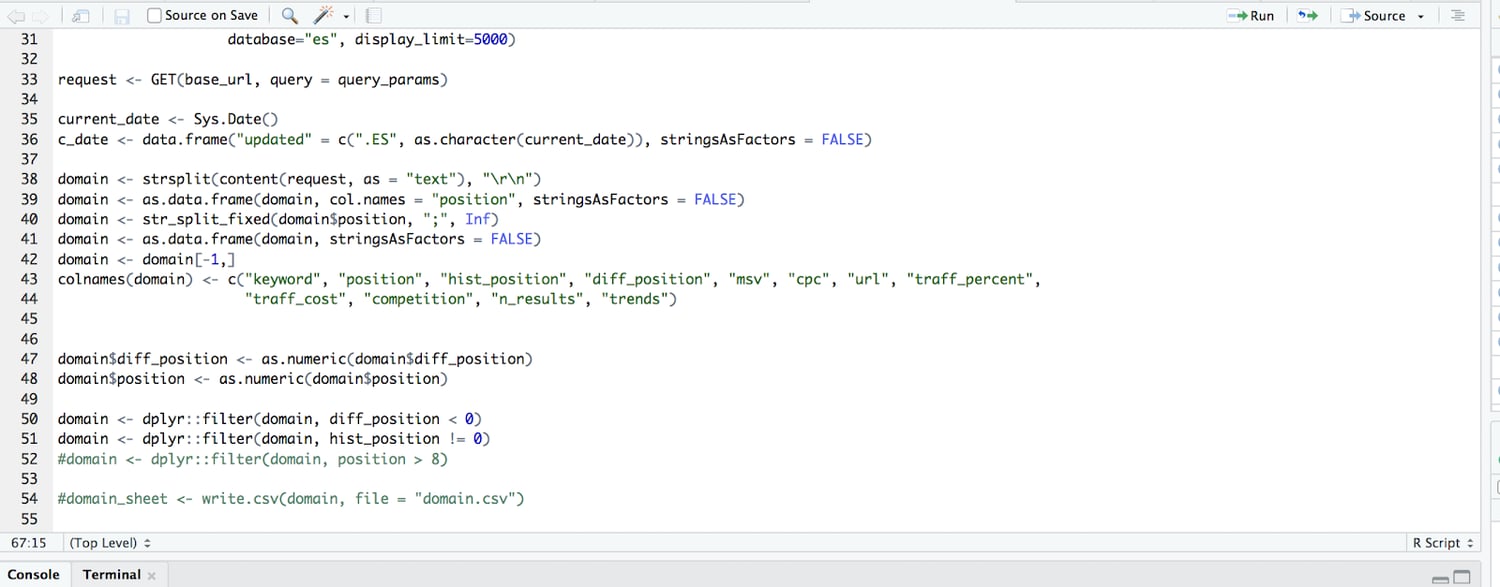
O que estamos fazendo no código acima, depois de extrair 10.000 linhas de dados de palavras-chave, é analisá-los da API para que sejam legíveis e, em seguida, construí-los em uma tabela de dados. Em seguida, subtraímos a classificação atual da classificação anterior para obter a diferença na classificação (então, se costumávamos classificar na posição 4 e agora classificamos 9, a diferença na classificação é -5).
Filtramos ainda mais, de forma que apenas destacamos aquelas com uma diferença na classificação de valor negativo (apenas palavras-chave para as quais perdemos classificações, não aquelas que ganhamos ou que permaneceram as mesmas).
Em seguida, enviamos essa tabela de dados limpa e filtrada para o Planilhas Google, onde aplicamos toneladas de fórmulas personalizadas e formatação condicional.
Finalmente, precisávamos saber: quais são os resultados e como realmente tomamos decisões ao otimizar o conteúdo?
3. Resultados da ferramenta de conteúdo em risco: como tomamos decisões
Dadas as colunas de entrada (palavra-chave, posição atual, posição histórica, a diferença de posição e o volume de pesquisa mensal) e as fórmulas acima, calculamos uma variável categórica para uma saída.
Um URL / linha pode ser um dos seguintes:
- “EM RISCO”
- “VOLÁTIL”
- Em branco (sem valor)
Saídas em branco , ou aquelas linhas sem valor, significam que podemos essencialmente ignorar esses URLs por enquanto. Eles não perderam uma quantidade significativa de classificação ou já estavam na página 2 do Google.
“Volátil” significa que a página está caindo no ranking, mas ainda não é um post de blog antigo o suficiente para justificar qualquer ação. Novas páginas da web saltam nos rankings o tempo todo à medida que envelhecem. Em um determinado ponto, eles geram “autoridade de tópico” suficiente para permanecer por um tempo, em geral. Para conteúdo de suporte ao lançamento de um produto ou uma campanha de marketing crítica, podemos dar a essas postagens um pouco de TLC, pois ainda estão amadurecendo, portanto, vale a pena sinalizá-las.
“Em risco” é principalmente o que buscamos – postagens de blog que foram publicadas há mais de seis meses, caíram no ranking e agora estão entre as posições 8 e 10 para uma palavra-chave de alto volume. Vemos isso como a “zona vermelha” para conteúdo com falha, onde está a menos de 3 posições de cair da página 1 para a página 2 do Google.
A fórmula da planilha para essas três marcas está abaixo – basicamente uma declaração IF composta para encontrar classificações da página 1, uma diferença de classificação negativa e a distância da data de publicação do dia atual.

O que aprendemos
Resumindo, funciona! A ferramenta descrita acima tem sido uma adição regular, se não frequente, ao nosso fluxo de trabalho. No entanto, nem todas as atualizações preditivas economizam tráfego na hora certa. No exemplo abaixo, vimos uma postagem do blog cair da página 1 após uma atualização e, posteriormente, retornar a uma posição superior.
E tudo bem.
Não temos controle sobre quando e com que frequência o Google decide rastrear novamente uma página e reclassificá-la.
Claro, você pode reenviar o URL ao Google e pedir que eles façam um novo rastreamento (para conteúdo crítico ou urgente, essa etapa extra pode valer a pena). Mas o objetivo é minimizar a quantidade de tempo que esse conteúdo apresenta desempenho inferior e estancar o sangramento – mesmo que isso signifique deixar a rapidez da recuperação ao acaso.
Embora você nunca saiba realmente quantas visualizações de página, leads, inscrições ou assinaturas você pode perder em cada página, os cuidados que você toma agora vão economizar tempo que você gastaria tentando identificar por que o tráfego total de seu site caiu Semana Anterior.
Warning: Attempt to read property "roles" on bool in /home/cvmarj.com.br/public_html/blog/wp-content/plugins/booster-extension/inc/frontend/author-box-shortcode.php on line 20
Warning: Trying to access array offset on value of type null in /home/cvmarj.com.br/public_html/blog/wp-content/plugins/booster-extension/inc/frontend/author-box-shortcode.php on line 20
Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %